
척척석사가 되어보자
0. Supervised Learning 본문
유튜브 딥러닝 강좌와 머신러닝 개념을 잘 설명해준 블로그를 참고하여 공부하려 한다.
유튜브 강좌 : https://www.youtube.com/channel/UCML9R2ol-l0Ab9OXoNnr7Lw
블로그 : https://laonple.blog.me/220463627091
유튜브와 블로그를 공부한 토대로 복습 내용 적기.
1. Supervised Learning : 입력 + 출력 = > 모델을 만든다.
2. unsupervised Learning : 정답은 모르는 상태, 입력값만을 이용하여 모델을 만든다. 따라서 classification, auto-tagging등에 사용된다.
3. reinforcement Learning : 로봇이 행동에 따라 칭찬과 벌을 받아 행동을 강화하여 학습한다.
1. Supervised Learning
: 트레이닝 된 데이터를 참고하여 규칙을 만들어 모델을 형성하고 새로운 데이터에 대해 추측가능하게 한다.
입력과 출력을 모두 받는다.
입력은 보통 특징들을 뽑아내어 벡터값으로 표현한다.
좋은 트레이닝 set을 뽑아내는것이 중요하다.
많은 트레이닝 set이 필요하다.
범주화 (generalization)이 잘 되어있어야 한다.
Types of Supervised Learning
(1) regression : ex) output이 0~100까지 linear한 숫자로 나와야 하는 경우
(2) classification : ex) 고양이, 개 등을 분류하는 경우
(3) multi level classification : ex) 성적을 A,B,C,D,E,F 등을 부여하는 경우
Supervised Learning 알고리즘의 종류
-Artificial neural network

가중치를 설정하여 output의 값을 조절.
기본적 모델 : y(출력) = w(가중치)*x(입력) +b
-Boosting
샘플을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계하는 방법인 Bagging과 달리,
Boosting은 맞추기 어려운 문제에 더 가중치를 더해 많이 틀리는 문제에 초점을 맞춤.
-Bayesian statistics

확률과 그래프를 이용하여 모델을 만들고, 그래프의 의존성(화살표 방향대로 의존. ex)구름이 끼면 비가 내린다.)
에 의거해 결과를 통계적으로 예측함.
-Decision tree

스무고개 놀이 하듯이 질문을 던져 대상을 좁혀나가 찾고 싶은 분류의 정답을 구해냄.
(출처 : https://ratsgo.github.io/machine%20learning/2017/03/26/tree/ )
-Gaussian process regression
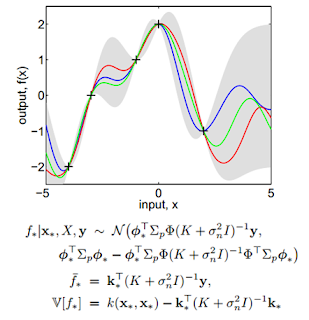
관측된 데이터를 통해 여러개의 정규분포곡선을 겹쳐놓아 n-차원의 모델을 예측하는 방법.
(출처 : http://t-robotics.blogspot.com/2013/09/blog-post_20.html#.W45w_OgzZPY)
-Nearest neighbor algorithm
제일 근접한 데이터들을 묶어나가며 분류하는 방법.
-Support vector machine

클래스를 가장 잘 분류할 수 있는 hyperplane(위 그림에서는 직선)을 찾는 방법.
-Random forests
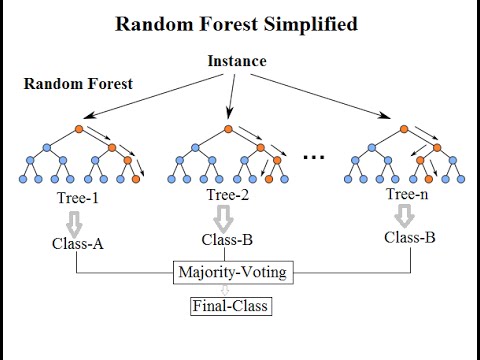
Random하게 training set을 뽑고, Random하게 bagging하여 decision tree에 적용시켜
가장 성능이 좋은 모델을 찾는 방법.
-Symbolic machine learning
human-readable concepts을 가진 machine learning .. ? 잘 모르겠다.
'머신러닝 > 개념공부' 카테고리의 다른 글
| 활성화 함수(Activation function) (0) | 2019.09.10 |
|---|---|
| logistic regression 개념 복습 (0) | 2018.10.12 |
| linear regression 개념 정리 (0) | 2018.09.11 |

